How a quiet luxury fashion brand built an institutional-grade competitive intelligence team without hiring one.
Parentezi is a quiet luxury womenswear brand. Their North Star is The Frankie Shop. Their competitors include Toteme, Tibi, St. Agni, DISSH. Each of those brands has a research department. Parentezi has one founder.
96 days ago, we changed that.












A sample of real deliveries the system has produced for the brand.
Real numbers from a real production system.
Aggregate metrics, refreshed every 10 minutes from the production database. No marketing arithmetic. No tenant-specific data exposed.
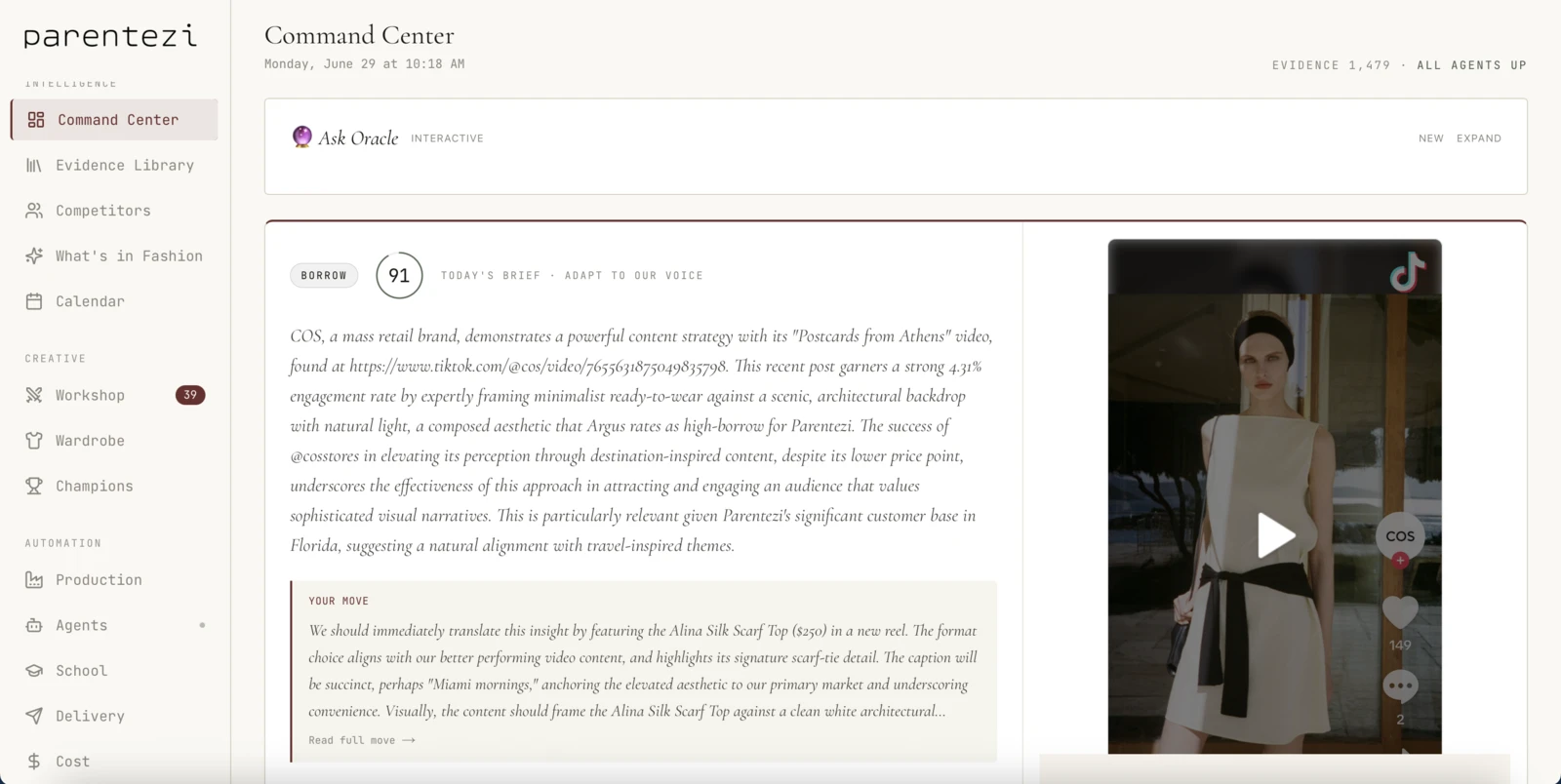
Not slides. Deliverables.
Reels, campaigns, and editorial stills the system produced and the studio approved — in the brand’s voice, on schedule.





Tibi has a research team. Toteme has one.
Most indie brands don’t.
THE OLD MATH
An institutional intelligence operation costs ~$200K/year all-in for one mid-level analyst. That’s $16,667/month before tools, before infrastructure, before the 6-month ramp before any meaningful output. And when they leave, the knowledge walks out with them.
THE WEDGE
What if a small fashion brand could have institutional-grade competitive intelligence at a tenth of the cost? With a 30-day deployment instead of a 6-month ramp? With knowledge that compounds in a database instead of walking out the door?
13 agents. One mission.
Each with a role. Each with a schedule.
Generates the daily 6:30 AM brief. Picks one product based on sales velocity, inventory health, and competitor signal.
Translates briefs into hero images, carousels, and reels. Veo + Gemini + DALL-E + ffmpeg fallback. Approval-gated.
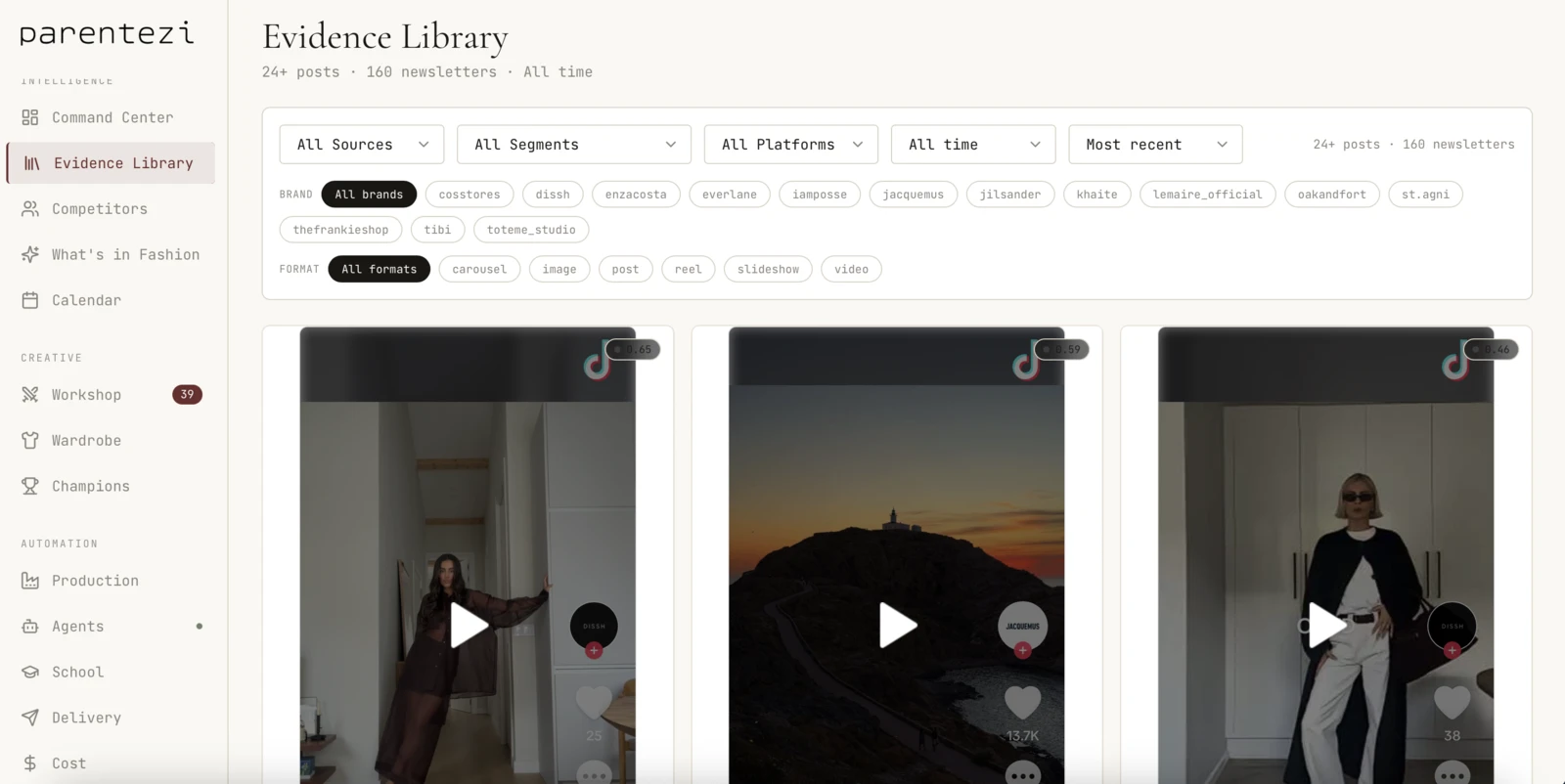
Scores every scraped competitor post for engagement, format, and aesthetic. Hundreds of posts in the library.
Specialized vision model for video content. Extracts hooks, transitions, and pacing patterns.
Pulls fresh Instagram and TikTok posts from tracked competitors every 6 hours.
Mirrors the Shopify catalog nightly. Inventory + sales velocity + new arrivals reconciled.
Checks every system every 5 minutes. Critical-vs-advisory severity classification keeps alerts meaningful.
Weekly RAG curation. Promotes high-impact learnings, archives noise. The system gets sharper every Sunday.
Refreshes the materialized sales summary view nightly. Cleopatra reads it to pick winners.
Processes orders daily. Surfaces AOV, geography, repeat behavior.
Sends the daily 7:30 AM email digest to the operations inbox.
Auto-exports approved deliveries to the brand's shared Drive folder.
Every morning at 6:30 AM Eastern, Cleopatra generates a brief grounded in real Shopify inventory, real competitor scrape data, and the captured learnings about what works for the brand specifically. By 7:30 AM, Liaison has sent the digest. By 10 AM, Caesar has begun production on approved concepts. The founder reviews on her phone over coffee.
The dashboard the operator runs
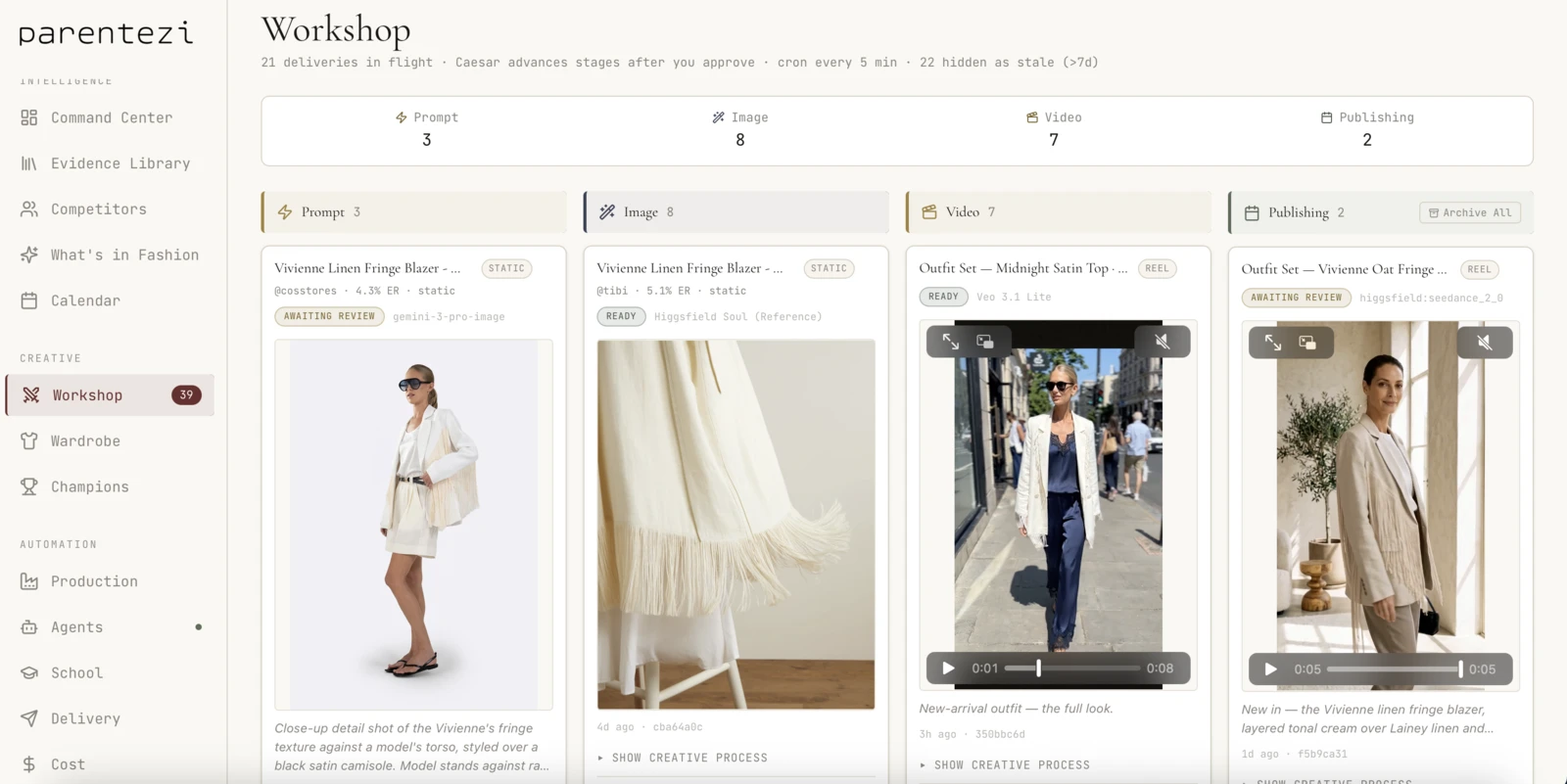
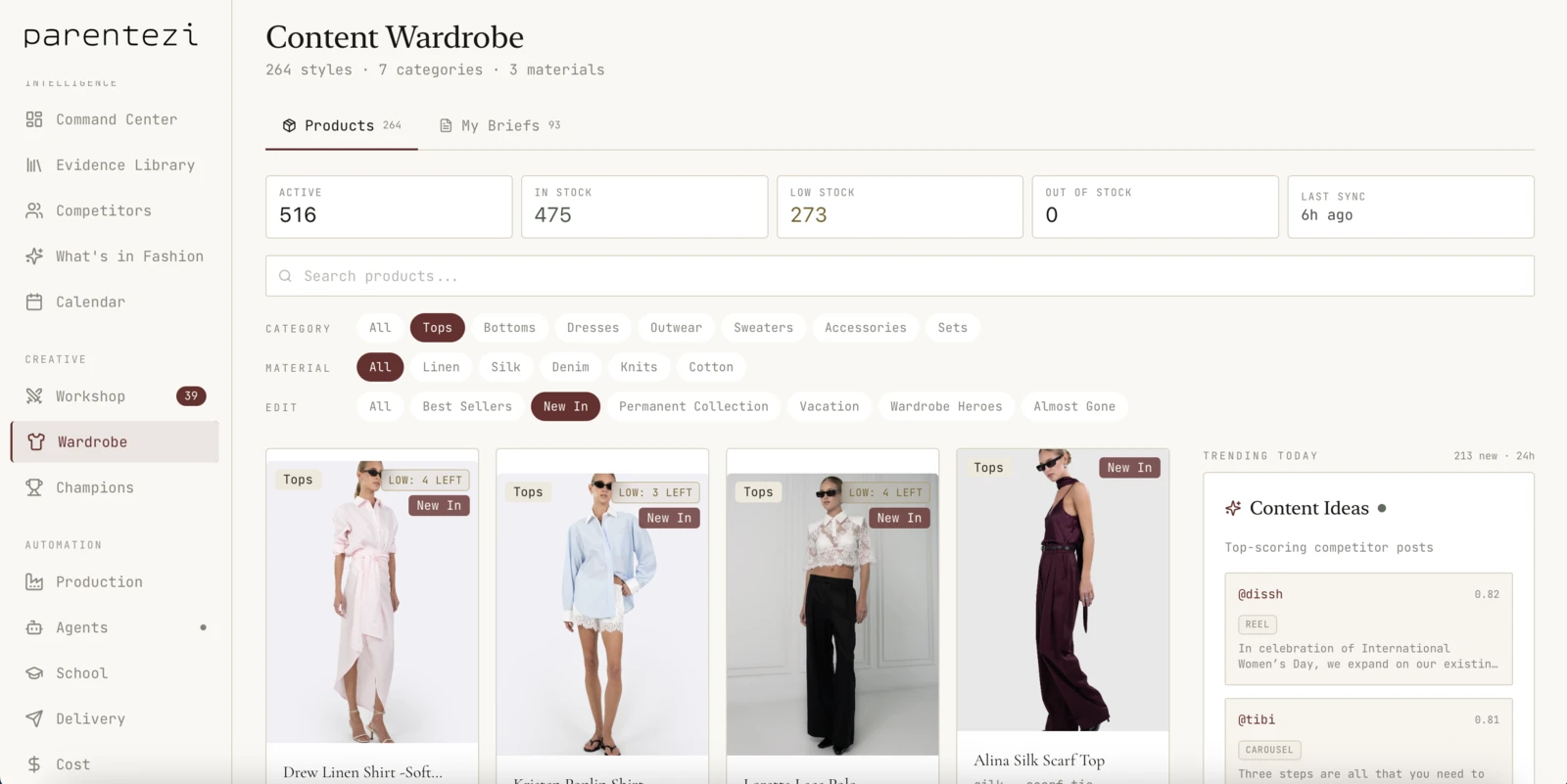
The system has captured 384+ learnings about how this brand wins.
Every approval, rejection, and correction — captured, scored, recalled. Here are the high-confidence ones it trusts most. Real entries from the production RAG layer.
“Detail shots outperform full-body by 30%. Always recommend detail/texture angles for hero products.”
“Video/reel format dominates top 100 evidence posts (70% of library). Default to reel for high-engagement products.”
“Best posting windows: Tuesday 11am, Wednesday 12pm, Thursday 6pm, Friday 5pm EST. Weekend posts show 15% lower engagement.”
“The Frankie Shop (North Star) uses near-zero captions. Caption brevity correlates with luxury perception.”
“Never lead with price. Never use discount framing. Price appears at end of caption only.”
By month six of any tenant, the RAG layer is so brand-specific it cannot be replicated by a competitor without the same volume of feedback. This is the moat. It’s why the second tenant takes longer to onboard than the first — but the third, fourth, and fifth are just provisioning.
From first config to production system.
A 698-byte config file.
The first openclaw.json. The original use case wasn't competitive intelligence — it was content production for our own agency. Pixar-format clay-stop-motion videos teaching agency lessons. Hilarious. Wonky. 75% functional. But it was moving. The agents had voices, the systems were talking, and the operator was reviewing output every morning.
The wedge insight crystallizes.
The agent infrastructure was real, but the use case was internal. We pointed it at a partner brand instead. From that day forward, the same agents that had been making clay animations started tracking real fashion competitors and producing real intelligence briefs. The wedge: keep the bones, change the use case.
The Frankie Shop replaces The Row as North Star.
The Row at $800-$3,500 is too aspirationally remote to teach concrete tactics. The Frankie Shop at $292 average is price-overlap territory with our partner brand. The founder had been telling us this for weeks. Today it became system gospel — and it changed every brief that followed.
The modern system comes online in a single day.
13 Supabase tables seeded. First agent_run. First catalog sync. First evidence post. First daily brief. Week one: 1,398 runs across 4 agents at 48% success. Half of everything broke. We rebuilt every broken piece in real-time and brought success rate back to 90%+ within 72 hours.
Phase 2 ships in 14 hours. 6 dispatches. 8 migrations.
Cleopatra learns commerce (sales velocity weighting). Caesar produces 3-frame carousels with reel retry + Ken Burns fallback. Sentinel's false-failure rate drops 78% → 0%. Curator goes live for weekly RAG hygiene. Workshop hygiene swept. The system becomes commercially aware — picking products based on what's selling, not just what's pretty.
83,028 agent runs and counting.
Tomorrow's brief fires at 6:30 AM whether anyone's awake or not. The system has run autonomously for 96 days. It has produced 144 deliveries, scored 1,639 evidence posts, and captured 384 things about how this brand wins. We didn't write any of those learnings. The system did.
Your brand is next.
Thirty minutes. We’ll map your operations, find the bottleneck, and show you what the first version looks like for your brand.
“Shoot for the moon. Even if you miss, you’ll land among the stars.”— Norman Vincent Peale
Map your highest-cost work — 30-minute strategy blueprint callLimited to 8 brand engagements in 2026 · Currently accepting Q2/Q3 deployments